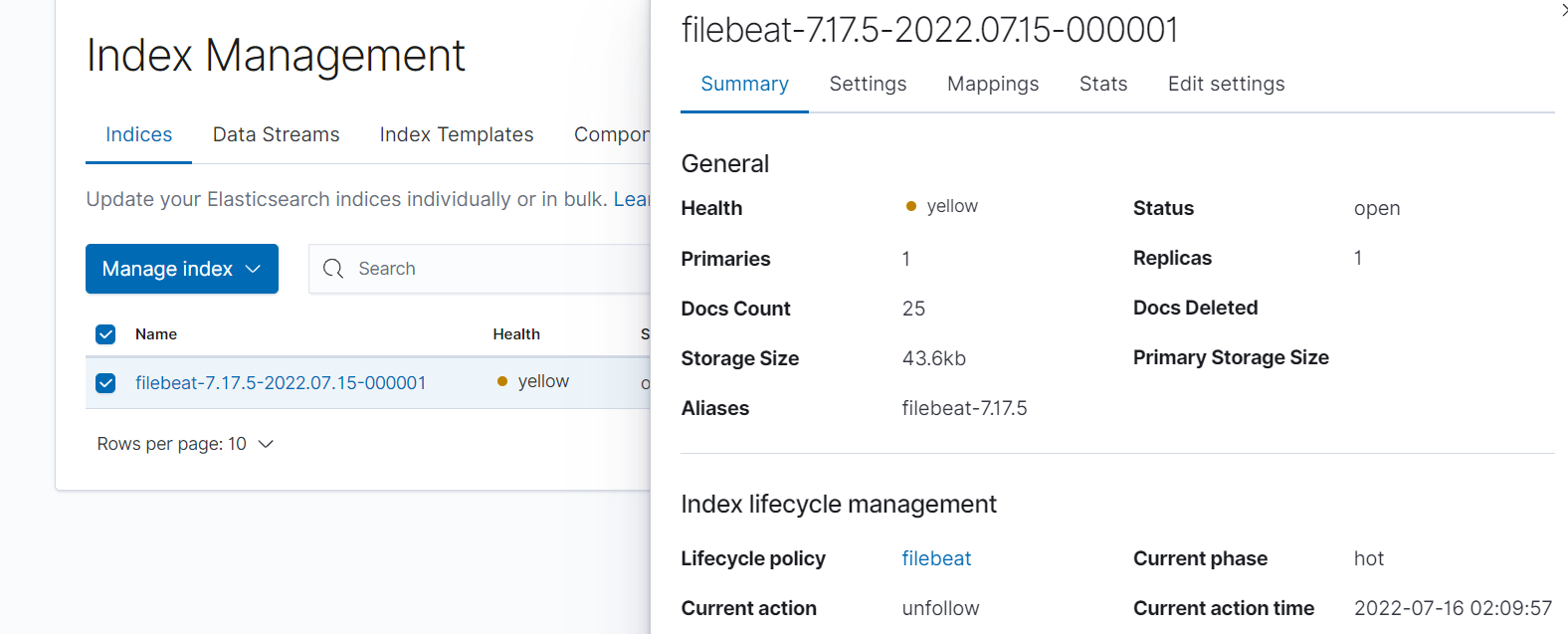
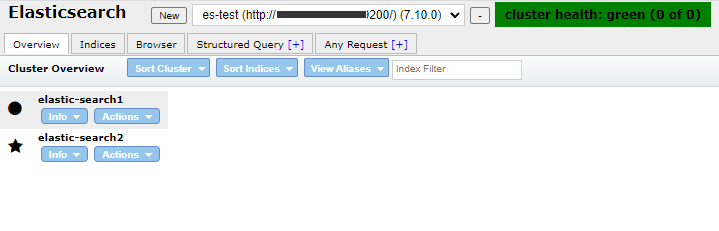
클러스터와 노드 여러개의 ES 프로세스들을 논리적으로 결합하여 하나의 ES 프로세스 처럼 사용할수 있게 해준다. 이때 클러스터를 구성하는 하나하나의 ES프로세스를 노드라고 부른다. 노드역할 노드역할 설명 마스터(Master Eligible) 클러스터 구성에서 중심이 되는 노드. 클러스터의 상태등 메타데이터를 관리한다. 데이터(Data) 사용자의 문서를 실제로 저장하는 노드 인제스트(Ingest) 사용자의 문서가 저장되기 전 문서의 변환이 필요한 내용을 사전 처리하는 노드 코디네이트(Coordinate) 사용자의 요청을 데이터 노드로 전달하고, 다시 데이터 노드로부터 결과를 취합하는 노드 위 표와 같이 노드가 할 수 있는 역할은 총 4가지 이며, 각각 하나의 역할만 할 수 있는게 아니라 한번에 여러개의 역..