우리는 토픽으로부터 데이터를 읽어 오는 작업을 확장할수 있어야 한다. 여러개의 컨슈머가 같은 토픽으로 부터 데이터를 분할해서 읽어올 수 있게 해야 하는것이다. 카프카 컨슈머는 보통 컨슈머 그룹의 일부로써 작동한다. 동일한 컨슈머 그룹에 속한 여러개의 컨슈머들이 동일한 토픽을 구독할 경우, 각각의 컨슈머는 해당 토픽에서 서로 다른 파티션의 메시지를 받는 것이다.
파티션보다 더 많은 컨슈머를 추가한다면 컨슈머 중 몇몇은 유휴 상태가 되어 메시지를 전혀 받지 못한다. 이것은 토픽을 생성할 때 파티션 수를 크게 잡아주는게 좋은 이유이기도 한데, 부하가 증가함에 따라서 더 많은 컨슈머를 추가할 수 있게 해주기 때문이다.
여러 애플리케이션이 동일한 토픽에서 데이터를 읽어와야 하는 경우 역시 매우 흔하다. 카프카의 주 디자인 목표 중 하나는 토픽에 쓰여진 데이터를 전체 조직안에서 여러 용도로 사용할 수 있도록 만드는 것이었다.
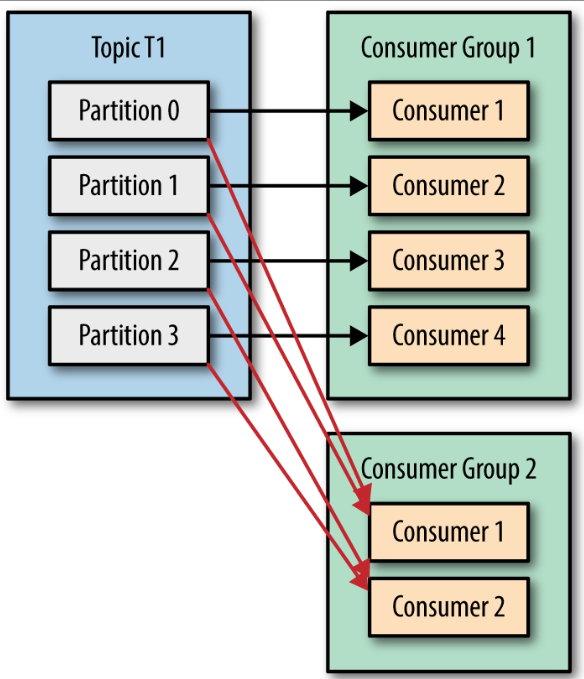
컨슈머 그룹과 파티션 리벨런스
컨슈머 그룹에 속한 컨슈머들은 자신들이 구독하는 토픽의 파티션들에 대한 소유권을 공유한다. 컨슈머에 파티션을 재할당하는 작업은 컨슈머 그룹이 읽고 있는 토픽이 변경되었을 때도 발생한다. (예, 운영자가 토픽에 새 파티션을 추가했을 경우), 컨슈머에 할당된 파티션을 다른 컨슈머에게 할당해주는 작업을 '리벨런스' 라고 한다. 리벨런스는 컨슈머 그룹에 높은 가용성과 규모 가변성을 제공하는 기능이기 때문에 매우 중요하지만, 문제없이 작업이 수행되고 있는 와중이라면 그리 달갑지 않은 기능이기도 하다.
조급한 리벨런스
모든 컨슈머는 읽기 작업을 멈추고 자신에게 할당된 모든 파티션에 대한 소유권을 포기한 뒤, 컨슈머 그룹에 다시 참여하여 완전히 새로운 파티션 할당을 전달받는다. 짧은 시간 동안 작업을 멈추게 한다.

협력적 리벨런스
점진적 리벨런스의 경우 한 컨슈머에게 할당되어 있던 파티션만을 다른 컨슈머에 재할당한다. 이 경우 리벨런싱은 2개 이상의 단계에 걸쳐서 수행된다. 두번째 단계에서는 컨슈머 그룹리더가 이 포기된 파티션들을 새로 할당한다. 막약 컨슈머가 일정 시간 이상 하트비트를 전송하지 않는다면, 세션 타임아웃이 발생하면서 그룹 코디네이는 해당 컨슈머가 죽었다고 간주하고 리벨런스를 실행한다. 컨슈머를 깔끔하게 닫아줄 경우 커슈머는 그룹 코디네이터에게 그룹을 나간다고 통지하는데, 그러면 그룹 코디네이터는 즉시 리벨런스를 실행함으로써 처리가 정지되는 시간을 줄인다.

정적 그룹 멤버십
컨슈머가 정적 멤버로서 컨슈머 그룹에 처음 참여하면 평소와 같이 해당 그룹이 사용하고 있는 파티션 할당 전략에 따라 파티션이 할당된다. 그리고 컨슈머가 다시 그룹에 조인하면 멤버십이 그대로 유지되기 때문에 리벨런스가 발생할 필요없이 예전에 할당 받았던 파티션들을 그대로 재할당받는다. 파티션 할당을 캐시해 두고 있기 때문에 정적 멤버가 다시 조인해 들어온다고 해서 리벨런스를 발생시키지는 않는다. (그냥 캐시되어 있는 파티션 할당을 보내주면 되는 것이다.)
정적 그룹 멤버십은 애플리케이션이 각 컨슈머에게 할당된 파티션의 내용물을 사용해서 로컬 상태나 캐시를 유지해야 할때 편리하다. 어떤 컨슈머도 이렇게 컨슈머를 잃어버린 파티션들로부터 메시지를 읽어오지 않을 것이기 때문에 정지되었던 컨슈머가 다시 돌아오면 이 파티션에 저장된 최신 메시지에서 한참 뒤에 있는 밀린 메시지부터 처리하게 된다. 정적멤버가 종료되었음을 알아차리는 것은 session.timeout.ms 설정에 달려있다. 시간동안 작동이 멈출경우 자동으로 파티션 재할당이 이루어져서 오랫동안 파티션 처리가 멈추는 상황을 막을 수 있을 만큼 충분히 작은 값으로 설정할 필요가 없다.
카프카 컨슈머 생성하기 (Deserializer 적용)
메시지 발행을 위한 Kafka Client가 필요하다.
import { Injectable } from '@nestjs/common';
import { KafkaJS } from '@confluentinc/kafka-javascript';
import * as dotenv from 'dotenv';
dotenv.config();
@Injectable()
export class KafkaClientService {
private readonly kafka: KafkaJS.Kafka;
private readonly consumer: KafkaJS.Consumer;
constructor() {
// ---- KafkaJS client connect ----
this.kafka = new KafkaJS.Kafka({
kafkaJS: {
clientId: process.env.KAFKA_CLIENT_ID ?? 'your-client-id',
brokers: [process.env.KAFKA_BROKER ?? 'your-broker'],
ssl: true,
sasl: {
mechanism: 'plain',
username: process.env.KAFKA_API_KEY ?? 'your-api-key',
password: process.env.KAFKA_API_SECRET ?? 'your-secret',
},
},
});
this.consumer = this.kafka.consumer({
'group.id': process.env.KAFKA_GROUP_ID ?? 'your-group',
});
}
// Get consumer client instance
getConsumer(): KafkaJS.Consumer {
return this.consumer;
}
}
그리고 동시에 SchemaRegistry와 integration할 Client도 필요하다.
import { Injectable, Logger } from '@nestjs/common';
import {
SchemaRegistryClient,
AvroSerializer,
AvroDeserializer,
SerdeType,
SchemaId,
AvroSerializerConfig,
AvroDeserializerConfig,
} from '@confluentinc/schemaregistry';
import { Schema, Type } from 'avsc';
@Injectable()
export class SchemaConfluentRegistryService {
private readonly registry: SchemaRegistryClient;
private readonly serializer: AvroSerializer;
private readonly deserializer: AvroDeserializer;
private readonly logger = new Logger(SchemaConfluentRegistryService.name);
constructor() {
this.registry = new SchemaRegistryClient({
baseURLs: [
process.env.SCHEMA_REGISTRY_URL ?? 'https://your-schema-registry-url',
],
basicAuthCredentials: {
credentialsSource: 'USER_INFO',
userInfo: `${process.env.SCHEMA_REGISTRY_API_KEY}:${process.env.SCHEMA_REGISTRY_API_SECRET}`,
},
});
// Initialize deserializer
const avroDeserializerConfig: AvroDeserializerConfig = {};
this.deserializer = new AvroDeserializer(
this.registry,
SerdeType.VALUE,
avroDeserializerConfig,
);
}
/**
* Decode a message using the normal deserialization process.
* @param topic : string - Kafka topic name
* @param payload : Buffer - The message payload to decode
* @returns {Promise<Buffer>}
* @throws Error if decoding fails
* Usage:
* const decoded = await schemaService.decodeMessageNormal('my-topic', messageBuffer);
*/
async decodeMessageNormal(
topic: string,
payload: Buffer,
): Promise<Record<string, any>> {
try {
// Deserialize the message
return (await this.deserializer.deserialize(topic, payload)) as Buffer;
} catch (error) {
this.logger.error('Error decoding message:', error);
throw error;
}
}
/**
* Track schema validation errors
* @param type : Type - The Avro schema type
* @param payload : any - The payload to validate
* @returns string[] - An array of validation error messages, empty if valid
*/
getSchemaErrors(type: Type, payload: any): string[] {
const errors: string[] = [];
const isValid = type.isValid(payload, {
errorHook: (path, value, type) => {
errors.push(
`Field error at ${path.join('.') || '(root)'}: expected ${type.toString()}, got ${value}`,
);
},
});
return isValid ? [] : errors;
}
}Application Layer에서 쉽게 사용할 수 있도록 어느정도 정형화해서 패키징 하였다.
import { KafkaJS } from '@confluentinc/kafka-javascript';
import {
Injectable,
Logger,
OnModuleDestroy,
OnModuleInit,
} from '@nestjs/common';
import { KafkaClientService } from './kafka-client.service';
import { SchemaConfluentRegistryService } from './schema-client.service';
import { KAFKA_TOPICS } from '@common/constant';
import { EventEmitter2 } from '@nestjs/event-emitter';
@Injectable()
export class ConfluentConsumeService implements OnModuleInit, OnModuleDestroy {
private readonly logger = new Logger(ConfluentConsumeService.name);
private readonly consumer: KafkaJS.Consumer;
constructor(
private readonly kafkaClientService: KafkaClientService,
private readonly confluentRegistry: SchemaConfluentRegistryService,
private readonly eventEmitter: EventEmitter2,
) {
this.consumer = this.kafkaClientService.getConsumer();
}
async onModuleInit() {
await this.consumer.connect();
this.logger.log('✅ Confluent Kafka Consumer connected !');
const topics = Object.values(KAFKA_TOPICS);
await Promise.all(
topics.map((topic) => this.consumer.subscribe({ topic })),
);
await this.consumer.run({
eachMessage: async ({ topic, message }) => {
if (!message.value) return;
try {
const decoded: Record<string, any> =
await this.confluentRegistry.decodeMessageNormal(
topic,
message.value,
);
this.eventEmitter.emit(`kafka.${topic}`, { topic, data: decoded });
} catch (err) {
this.logger.error(`Error decoding message from ${topic}`, err);
}
},
});
}
async onModuleDestroy() {
await this.consumer.disconnect();
this.logger.log('❌ Confluent Kafka Consumer disconnected !');
}
}
Polling을 위한 리스너는 이렇게 사용한다.
@EventPattern(KAFKA_TOPICS.TOPIC_A)
async handleUserCreated(@Payload() message: Buffer) {
const registry = await this.schemaRegistryService.decodeMessageNormal(
KAFKA_TOPICS.TOPIC_A,
message,
);
this.logger.log(`Encoded message: ${JSON.stringify(registry)}`);
}
폴링 루프
컨슈머 API의 핵심은 서버에 추가 데이터가 들어왔는지 폴링하는 단순한 루프다. 이 루프는 무한 루프이기 때문에 종료되지 않는다. 컨슈머 애플리케이션은 보통 계속해서 카프카에 추가 데이터를 폴링하는, 오랫동안 돌아가는 애플리케이션이다.
컨슈머 설정하기
- fetch.min.bytes : 레코드를 얻어올 때 받는 데이터의 최소량를 지정할 수 있게 해준다. 충분한 메시지를 보낼 수 있을 때까지 기다린뒤 컨슈머에게 레코드를 보내준다. 이것은 토픽에 새록운 메시지가 많이 들어오지 않거나 하루중 쓰기 요청이 적은 시간대일 대와 같은 상황에서 오가는 메시지를 줄임으로써 컨슈머와 브로커 양쪽에 대해 부하를 줄여주는 효과가 있다.
- fetch.max.wait.ms : 충분한 데이터가 모일 때까지 기다리도록 할 수 있다. fetch.max.wait.ms는 얼마나 오래 기다릴 것인지를 결정한다.
- fetch.max.bytes : 폴링할 때 카프카가 리턴하는 최대 바이트 수를 지정한다.(기본값은 50MB) 이것은 컨슈머가 서버로 부터 받은 데이터를 저장하기 위해 사용하는 메모리양을 제한하기 위해 사용한다.
- max.poll.records : poll()을 호출할 때마다 리턴되는 최대 레코드 수를 지정한다.
- max.partition.fetch.bytes : 서버가 파티션별로 리턴하는 최대 바이트 수를 결정한다. (기본값은 1MB)
- session.timeout.ms(hearbeat.interval.ms) : 컨슈머가 브로커와 신호를 주고받지 않고도 살아 있는 것으로 판정되는 최대 시간의 기본값은 10초다.
- max.poll.interval.ms : 하트비트는 백그라운드 스레드에 의해 전송된다. 카프카에서 레코드를 읽어오는 메인 스레드는 데드락이 걸렸는데 백드라운드 스레드는 멀쩡히 하트비트를 전송하고 있을 수도 있다. 이럴때 죽었다고 판정할 수 있는 지표이다.
- default.api.timeout.ms : API를 호출할때 명시적인 타임아웃을 지정하지 않는한, 거의 모든 컨슈머 API호출에 적용되는 타임아웃 값이라고 할 수 있다.
- request.timeout.ms : 컨슈머가 브로커로부터의 응답을 기다릴 수 있는 최대 시간이다.
- auto.offset.reset : 기본값은 'latest'인데, 이것은 만약 유효한 오프셋이 없을 경우 컨슈머는 가장 최신 레코드부터 읽기 시작한다.
- enable.auto.commit : 이 매개변수는 컨슈머가 자동으로 오프셋을 커밋할지의 여부를 결정한다.(기본값 true). 언제 오프셋을 커밋할지를 직접 결정하고 싶다면 이 값을 false로 놓으면 된다. 만약 이값을 true로 놓은 경우, auto.commit.interval.ms를 사용해서 얼마나 자주 오프셋이 커밋될지를 제어할 수 있다.
- partition.assignment.strategy :
- Range : 각 토픽의 홀수 개의 파티션을 가지고 있고, 각 토픽의 할당이 독립적으로 이루어지기 때문에 첫 번째 컨슈머는 두 번째 컨슈머보다 더 많은 파티션을 할당 받게 된다.
- RoundRobin : 순차적으로 하나씩 컨슈머에 할당해 준다.
- Sticky : 첫번째는 파티션들을 가능한 한 균등하게 할당하는 것이고, 두번째는 리벨런스가 발생했을때 가능하면 많은 파티션들이 같은 컨슈머에게 할당되게 함으로써 할당된 파티션을 하나의 파티션을 하나의 컨슈머에서 다른 컨슈머로 옮길때 발생하는 오버헤드를 최소화 하는것이다.
- Cooperative Sticky : Sticky 할당자와 기본적으로 동일하지만, 컨슈머가 재할당되지 않는 파티션으로부터 레코드를 계속해서 읽어 올 수 잇도록 해주는 협력적 리벨런스 기능을 지원한다.
- client.id : 브로커가 요청을 보낸 클라이언트를 식별하는데 쓰인다.
- client.rack : client.rack 설정을 잡아 줌으로써 클라이언트가 위치한 영역을 식별할 수 있게 해줘야한다.
- group.instance.id : 컨슈머에 정적 그룹 멤버십 기능을 적용하기 위해 사용되는 설정
- receive.buffer.bytes / send.buffer.bytes : 데이털르 읽거나 쓸때 소켓이 사용하는 TCP의 수신 및 수신 버퍼의 크기를 가리킨다. -1로 잡아주면 운영체제 기본값이 사용된다.
- offsets.retention.minutes : 컨슈머 그룹이 비게되면 카프카는 커밋된 오프셋을 이 설정값에 지정된 기간 동안만 보존한다. (기본값 7일)
오프셋과 커밋
대신, 컨슈머가 카프카를 사용해서 각 파티션에서의 위치를 추적할 수 있게 한다. 카프카에서는 파티션에서의 현재 위치를 업데이트하는 작업을 오프셋 커밋이라고 부른다. 카프카는 레코드를 개별적으로 커밋하지 않는다. 컨슈머는 파티션에서 성공적으로 처리해 낸 마지막 메시지를 커밋함으로써 그 앞의 모든 메시지들 역시 성공적으로 처리되었음을 암묵적으로 나타낸다.
이것은 카프카에 특수 토픽인 __consumer_offset 토픽에 각 파티션별로 커밋된 오프셋을 업데이트하도록하는 메시지를 보냄으로써 이루어진다. 리벨런스 이후 각각의 컨슈머는 리벨런스 이전에 처리하고 있던 것과는 다른 파티션들을 할당받을 수 있다. 어디서부터 작업을 재개해야하는지를 알기 위해 컨슈머는 각 파티션의 마지막으로 커밋된 메시지를 읽어온 뒤 거기서 부터 처리를 재개한다.
자동커밋
enable.auto.commit 설정을 true로 잡아주면 컨슈머는 5초에 한번. poll()을 통해 받은 메시지 중 마지막 메시지의 오프셋을 커밋한다. 5초 간격은 기본값으로, auto.commit.interval.ms 설정을 잡아 줌으로써 바꿀수 있다. poll()메서드를 실행할때 마다 컨슈머는 커밋해야 하는지를 확인한뒤 그러할 경우에는 마지막 poll() 호출에서 리턴된 오프셋을 커밋한다.
자동 커밋은 편리하다. 그러나 개발자가 중복 메시지를 방지하기에는 충분하지 않다.
현재 오프셋 커밋하기
enable.auto.commit=false로 설정해줌으로써 애플리케이션이 명시적으로 커밋하려 할 때문 오프셋이 커밋되게 할 수 있다. 가장 간단하고 또 신뢰성 있는 커밋 API는 commitSync()이다. 이 API는 poll()이 리턴한 마지막 오프셋을 커밋한 뒤 커밋이 성공적으로 완료되면 리턴, 어떠한 이유로 실패하면 예외를 발생시킨다.
try (KafkaConsumer<String,String> c = new KafkaConsumer<>(p)) {
c.subscribe(List.of("orders"));
while (running) {
ConsumerRecords<String,String> recs = c.poll(Duration.ofMillis(500));
for (ConsumerRecord<String,String> r : recs) {
process(r); // 업무 로직
}
c.commitAsync((offsets, ex) -> { // 빠른 루프
if (ex != null) log.error("async commit fail", ex);
});
}
// 정상 종료 시 마지막 배치 보증
c.commitSync();
}
비동기적 커밋
수동 커밋의 단점 중 하나는 브로커가 커밋 요청에 응답할 때까지 애플리케이션이 블록된다는 점이다. 이것은 애플리케이션의 처리량을 제한하게 된다. 이 방식의 단점은 commitSync()가 성공하거나 재시도 불가능한 실패가 발생할 때까지 재시도하는 반면, commitAsync()는 재시도를 하지 않는다는 점이다.
동기적 커밋과 비동기적 커밋을 함께 사용하기
Duration timeout = Duration.ofMillis(100);
try {
while (!closing) { // 애플리케이션이 닫히지 않았다면
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
// 레코드 처리
}
consumer.commitAsync(); // 평소에는 빠르고 비동기적인 커밋 사용
}
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
try {
consumer.commitSync(); // 애플리케이션 종료 직전에는 동기적으로 확실하게 커밋
// 컨슈머를 닫는 상황에는 다음 커밋이 없으므로 commitSync()를 호출한다. 커밋이 성공하거나 회복 불가능한 에러가 발생할 때까지 시도함
} finally {
consumer.close(); // 컨슈머 종료
}
}
정상적인 상황에서는 commitAsync를 사용한다. 더 빠를 뿐더러 설령 커밋이 실패하더라도 다음 커밋이 재시도 기능을 하게 된다. 하지만 컨슈머를 닫는 상황에서는 '다음 커밋' 이라는 것이 있을 수 없으므로 commitSync()를 호출한다.
독립 실행 컨슈머, 컨슈머 그룹없이 컨슈머를 사용해야하는 이유와 방법
하나의 컨슈머가 토픽의 모든 파티션으로부터 모든 데이터를 읽어와야 하거나, 토픽의 특정 파티션으로부터 데이터를 읽어와야 할 때가 있다. 이러한 경우 컨슈머 그룹이나 리벨런스 기능이 필요하지는 않다.
'PaaS > MQ' 카테고리의 다른 글
| Kafka 심화) 신뢰성 있는 데이터 전달 (0) | 2026.01.23 |
|---|---|
| Kafka 심화) 카프카 내부 알고리즘 (0) | 2026.01.14 |
| Kafka 심화) Producer (0) | 2026.01.05 |
| TypeScript, NestJS로 Confluent Kafka 연결 3-Consumer 개발 (0) | 2025.09.01 |
| TypeScript, NestJS로 Confluent Kafka 연결 2-Producer 개발 (0) | 2025.09.01 |