728x90
Topic 생성
# ./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic peter-overview01 --partitions 1우선 프로듀서가 어떻게 디자인 되어 있는지를 살펴봅시다.
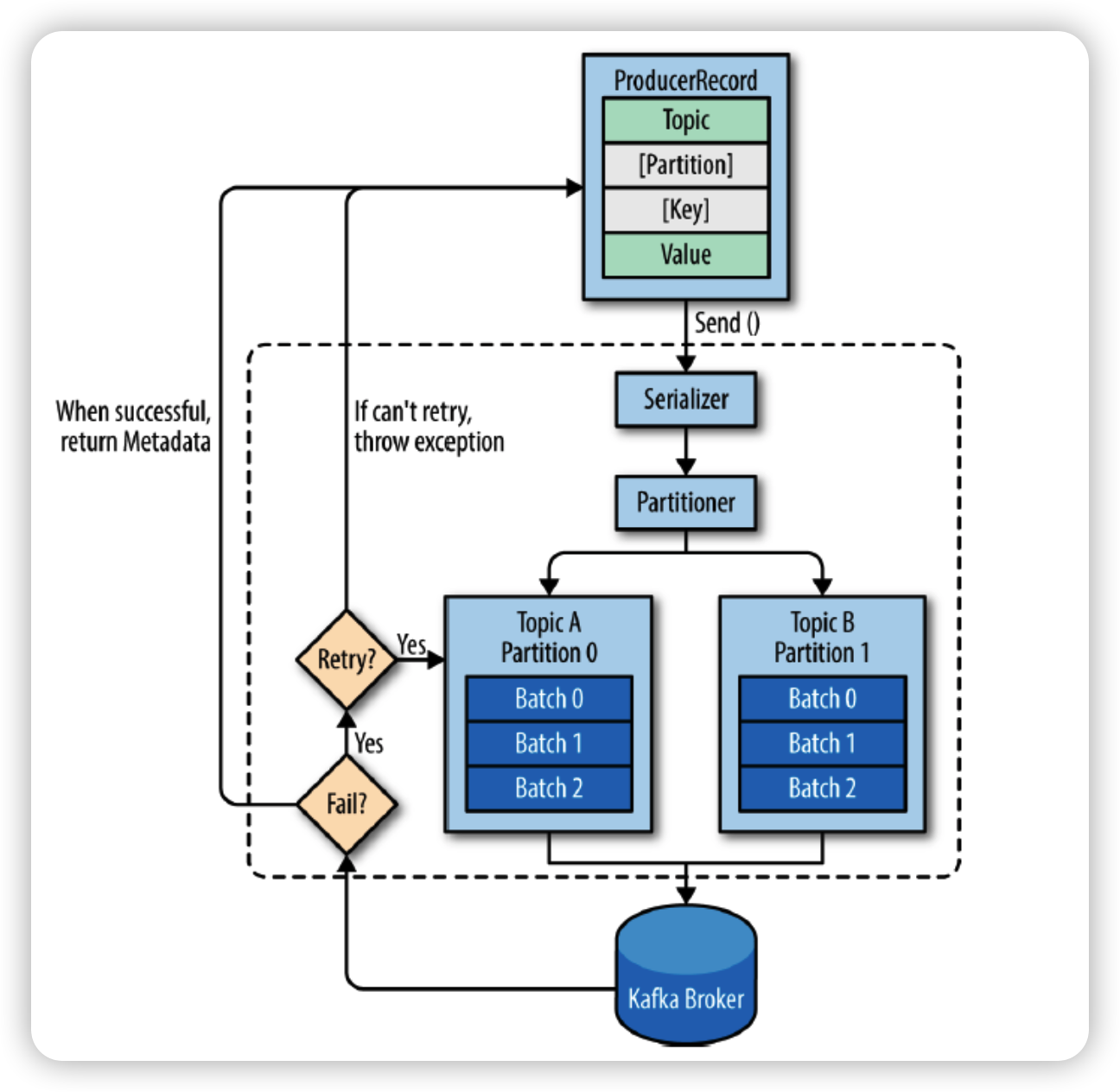
주요옵션
- bootstrap.servers
- 연결할 서버 정보입니다. host1:port1,host2:port2와 같이 여러개를 나열할 수 있습니다.
- 초기 커넥션 연결시에 사용하기 때문에, 모든 서버 리스트를 포함할 필요는 없습니다. 실제 메시지 전송시에는 새로운 커넥션을 맺은 다음에 전송하기 때문이지요.
- key.serializer, value.serializer
- 메시지를 serialize 할 때 사용할 클래스를 지정하면 됩니다.
- ByteArraySerializer, StringSerializer 등등 Serializer를 implements한 클래스들이 있습니다.
- partitioner.class
- 어떤 파티션에 메시지를 전송할지 결정하는 클래스입니다.
- 기본값은 DefaultPartitioner이며 메시지 키의 해시값을 기반으로 전송할 파티션을 결정합니다.
- acks
- 프로듀서가 전송한 메시지를 카프카가 잘 받은 걸로 처리할 기준을 말합니다.
- 0, 1, all 값으로 세팅할 수 있으며 각각 메시지 손실률과 전송 속도에 대해 차이가 있습니다.
- 설정값손실률속도설명
acks = 0 높음 빠름 프로듀서는 서버의 확인을 기다리지 않고
메시지 전송이 끝나면 성공으로 간주합니다.acks = 1 보통 보통 카프카의 leader가 메시지를 잘 받았는지만 확인합니다. acks = all 낮음 느림 카프카의 leader와 follower까지 모두 받았는지를 확인합니다. - 기본값은 acks=1 옵션입니다.
- buffer.memory
- 프로듀서가 서버로 전송 대기중인 레코드를 버퍼링하는데 사용할 수 있는 메모리 양입니다.
- 레코드가 서버에 전달될 수 있는 것보다더 빨리 전송되면 max.block.ms동안 레코드를 보내지 않습니다.
- 기본값은 33554432, 약 33MB입니다.
- retries
- 프로듀서가 에러가 났을때 다시 시도할 횟수를 말합니다.
- 0보다 큰 숫자로 설정하면 그 숫자만큼 오류 발생시에 재시도합니다.
- max.request.size
- 요청의 최대 바이트 크기를 말합니다. 대용량 요청을 보내지 않도록 제한할 수 있습니다.
- 카프카 서버에도 별도로 설정할 수 있으므로 서로 값이 다를 수 있습니다.
- connections.max.idle.ms
- 지정한 시간 이후에는 idle 상태의 연결을 닫습니다.
- max.block.ms
- 버퍼가 가득 찼거나 메타데이터를 사용할 수 없을 때 차단할 시간을 정할 수 있습니다.
- request.timeout.ms
- 클라이언트가 요청 응답을 기다리는 최대 시간을 정할 수 있습니다.
- 정해진 시간 전에 응답을 받지 못하면 다시 요청을 보내거나 재시도 횟수를 넘어서면 요청이 실패합니다.
- retry.backoff.ms
- 실패한 요청에 대해 프로듀서가 재시도하기 전에 대기할 시간을 말합니다.
- producer.type
- 메시지를 동기(sync), 비동기(async)로 보낼지 선택할 수 있습니다.
- 비동기를 사용하는 경우 메시지를 일정 시간동안 쌓은 후 전송하므로 처리 효율을 향상시킬 수 있습니다.
메시지 프로듀싱 예제
# ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic peter-overview01
다음 컨슈머의 동작에 대해서 살펴봅시다.
컨슈머 그룹은 하나 이상의 컨슈머들이 모여있는 그룹을 의미하고, 컨슈머는 반드시 컨슈머 그룹에 속하게 됩니다. 그리고 이 컨슈머 그룹은 각 파티션의 리더에게 카프카 토픽에 저장된 메시지를 가져오기 위한 요청을 보닙니다. 이때 파티션 수와 컨슈머 수는 일대일로 매핑되는 것이 이상적입니다. 물론 파티션 수와 컨슈머 수의 비율을 반드시 일대일로 매핑해야 하는 것은 아니지만 피티션 수보다 더 많다고 해서 더 빠르게 토픽의 메시지를 가져오거나 처리량이 높아지는 것이 아니라 더 많은 수의 컨슈머들이 그냥 대기 상태로만 존재하기 때문입니다. 간혹 액티브/스탠바이 개념으로 추가 컨슈머가 더 있으면 좋을 것이라고 생각할 수 도 있지만, 컨슈머 그룹내에서 리벨런싱 동작을 통해 장애가 발생한 컨슈머의 역할을 동일한 그룹에 있는 다른 컨슈머가 그 역할을 대신 수행하므로 굳이 장애 대비를 위한 추가 컨슈머 리소스를 할당하지 않아도 됩니다.
예를 들어 컨슈머01의 문제가 생겨 종료됐다면 컨슈머02 또는 03은 컨슈머 01이 하던일을 대신해 해당 토픽의 파티션0을 컨슘하기 시작한다.
주요옵션
- bootstrap.servers
- 카프카 클러스터에 처음 연결을 하귀 위한 호스트와 포트 정보로 구성된 리스트 정보를 나타낸다. 정의된 포맷은 호스트명:포트, 호스트명:포트, 호스트명:포트 이다.
- fetch.min.bytes
- 한번에 가져올 수 있는 최소 데이터 사이즈
- group.id
- 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자
- enable.auto.commit
- 백그라운드로 주기적으로 오프셋을 커밋합니다.
- auto.offset.reset
카프카에서 초기 오프셋이 없거나 현재 오프셋이 더 이상 존재하지 않은 경우에 다음 옵션으로 리셋합니다.- earliest: 가장 초기의 오프셋값으로 설정합니다.
- latest : 가장 마지막의 오프셋값으로 설정합니다.
- none : 이전 오프셋값을 찾지 못하면 에러를 나타냅니다.
- fetch.max.bytes
- 한번에 가져올 수 있는 최대 데이터 사이즈
- request.timeout.ms
- 요청에 대해 응답을 기다리는 최대 시간
- session.timeout.ms
- 컨슈머와 브로커사이의 세션 타임아웃 시간.
- heartbeat.interval.ms
- 그룹 코디네이터에게 얼마나 자주 KafkaConsumer poll()메소드로 하트비트를 보낼 것인지 조정합니다. session.timeout.ms와 밀접한 관계가 있으며 session.timeout.ms보다 낮아야 한다. 일반적으로 3분의 1정도로 설정한다.
- max.poll.records
- 단일 호출 poll()에 대한 최대 레코드 수를 조정합니다.
- max.poll.interval.ms
- 컨슈머가 하트비트만 보내고 메시지를 가져오지 않을 경우 무한정 해당 파티션을 점유할 수 없도록 주기적으로 poll을 호출하지 않으면 장애라고 판단하고 컨슈머 그룹에서 제외한 후 다른 컨슈머가 해당 파티션에서 메시지를 가져갈 수 있게 합니다.
- auto.commit.interval.ms
- 주기적으로 오프셋을 커밋하는 시간
- fetch.max.wait.ms
- fetch.min.bytes 에 의해 설정된 데이터보다 적은 경우 요청에 응답을 기다리는 최대 시간
메시지 컨슈밍 예제
# ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic peter-overview01
'PaaS > MQ' 카테고리의 다른 글
| kafka consumer의 내부 동작 원리와 구현 (0) | 2022.06.22 |
|---|---|
| kafka producer의 내부 동작 원리와 구현 (1) | 2022.06.14 |
| kafka 리플리케이션, 컨트롤러, 로그 (0) | 2022.06.14 |
| kafka 소개 및 개념 (0) | 2022.06.13 |
| kafka 서버 설치하기 (1) | 2022.06.07 |